Engineering Business & Management
Архитектура ИИ-ориентированных баз знаний: переход к Knowledge-as-Code
Переход корпоративного сегмента от традиционных систем управления знаниями к ИИ-ориентированным архитектурам знаменует собой фундаментальный сдвиг в работе с информацией. Классические платформы, полагающиеся на поиск по ключевым словам через инвертированные индексы, возлагают огромную когнитивную нагрузку на пользователя. Даже тщательно настроенные локальные инсталляции Confluence или Jira, развернутые in-house для защиты корпоративных данных, со временем неизбежно превращаются в цифровые кладбища.
Например, в крупных телекоммуникационных холдингах системные инженеры и аналитики могут тратить часы на поиск актуальных конфигураций инфраструктуры среди тысяч устаревших вики-страниц.
Новые системы работают принципиально иначе: используя векторные эмбеддинги и архитектуру RAG (Retrieval-Augmented Generation), они возвращают не ссылки на разрозненные файлы, а готовые синтезированные ответы.
Однако этот технологический скачок предъявляет экстремальные требования к качеству контента, поскольку устаревшие данные заставляют языковые модели опасно галлюцинировать.
В основе успешной трансформации лежит методология «Знания как код» (Knowledge-as-Code), которая стирает границу между привычной документацией для людей и строгими инструкциями для автономных ИИ-агентов. Бизнес-логика и описательные части теперь фиксируются в легковесном формате Markdown, в то время как вся инфраструктурная и ролевая информация выносится в машиночитаемые блоки YAML Frontmatter.
Выбор именно этих форматов продиктован суровой экономией вычислительных ресурсов. Тяжеловесный HTML или многоуровневый JSON съедают критически важный объем контекстного окна языковой модели из-за колоссального синтаксического шума, в то время как чистый Markdown позволяет токенизаторам фокусироваться исключительно на полезном сигнале.
Эффективность токенизации
Markdown минимизирует затраты токенов на синтаксис, оставляя больше места для контекста.
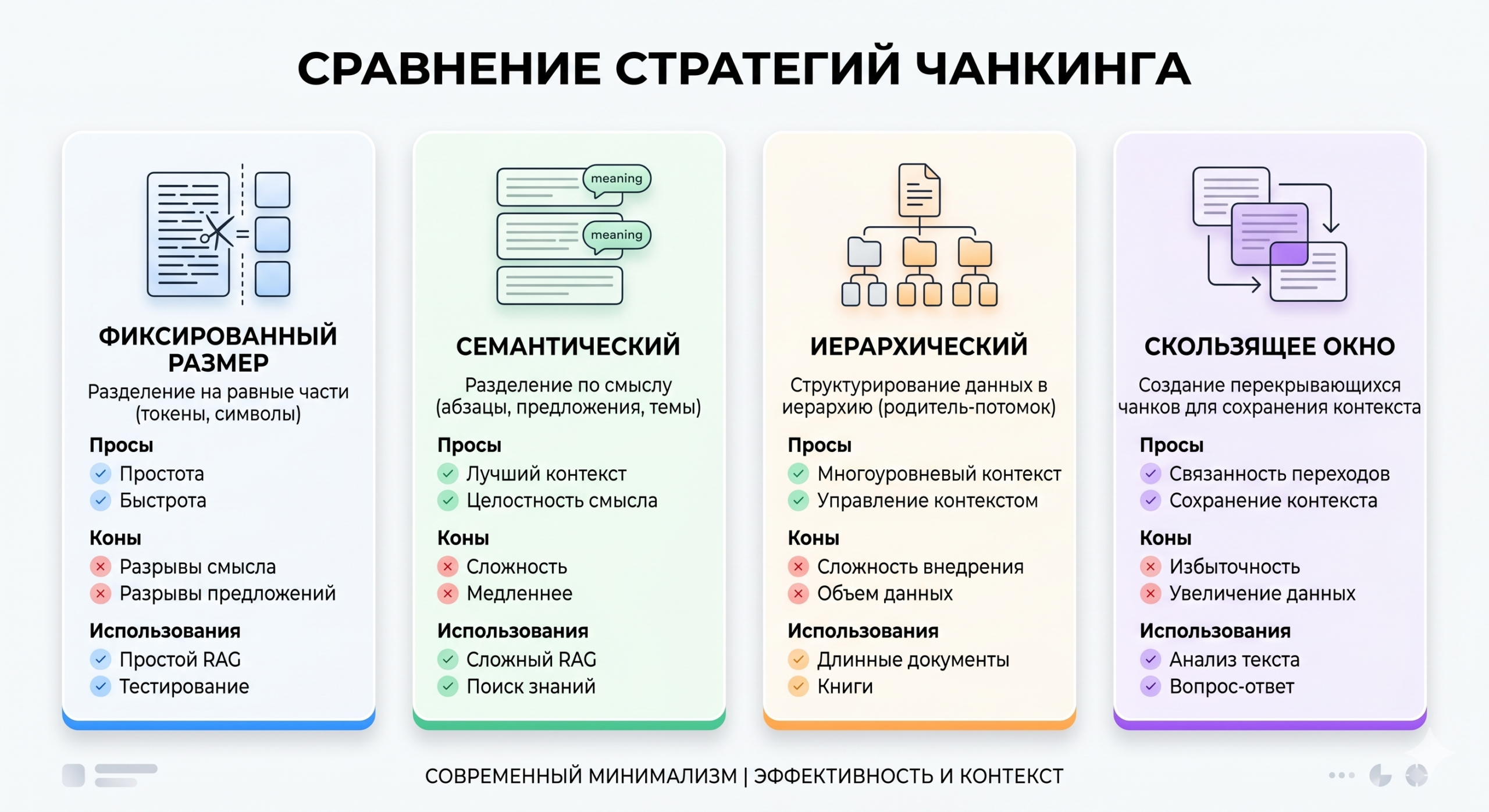
Для того чтобы алгоритмы поиска могли извлекать релевантные данные без потери смысла, применяется сложная стратегия фрагментации текста — чанкинг.
На ранних этапах цифровизации компании часто пытаются обойти проблему поиска с помощью самописных Python-скриптов, использующих нечеткую логику (fuzzy logic). Такие алгоритмы могут неплохо справляться со структурированными задачами, вроде автоматического сопоставления резюме кандидатов со штатным расписанием, но они абсолютно слепы к глубокому семантическому контексту сплошного текста. Поэтому для баз знаний внедряется пропозициональная сегментация и принцип «атомарных заметок», где каждый изолированный текстовый блок представляет собой завершенную мысль. При этом последние бенчмарки доказывают: структурно-ориентированный рекурсивный чанкинг часто выигрывает у сложного семантического разделения, так как надежно сохраняет целостность вложенных списков, таблиц и сниппетов кода.
Проблема точного поиска в высоконагруженных корпоративных средах окончательно решается переходом к гибридным поисковым моделям. Практика показала, что исключительно плотный векторный поиск (Dense Retrieval) прекрасно улавливает общий смысл пользовательского промпта, но катастрофически проваливается там, где требуется строгая лексическая точность — при поиске конкретных артикулов оборудования, IP-адресов или узкоспециализированных терминов.
Решением становится объединение векторов с классическими алгоритмами (например, BM25). Для бесшовной работы такого гибрида выстраивается жесткая архитектура метаданных, позволяющая осуществлять предварительную фильтрацию контента по номерам страниц, уровню вложенности заголовков и категориальным маркерам, отсекая до 90% нерелевантного шума еще до начала векторного сравнения.
Архитектура гибридного поиска
Практическая реализация таких систем требует развертывания глубоко интегрированных конвейеров автоматизации, которые зачастую хостятся на корпоративных VPS-серверах с использованием изолированных сред Docker для максимальной безопасности. Привычные текстовые редакторы в этом стеке эволюционируют в полноценные IDE для знаний — такие как Obsidian, где архитекторы могут визуализировать графы связей между документами. Визуальные платформы оркестрации, наподобие n8n, берут на себя всю рутину: они самостоятельно отслеживают новые коммиты в Git-репозиториях, запускают скрипты фрагментации, генерируют векторы и загружают их в базы данных вроде Chroma или Pinecone. В результате получается живая, самообновляющаяся экосистема, в которой ИИ-агенты могут мгновенно и безошибочно оперировать миллионами корпоративных записей.